AI/ML Pipeline Architecture
Models don't run themselves. The pipeline that trains, validates, deploys, and monitors your models is the actual product — the model is just one artifact.


When You Need This
You've proven an ML model works in a notebook. Now you need it in production — serving predictions at scale, retraining on new data, monitoring for drift, and rolling back when a new model performs worse than the current one. The gap between a working prototype and a production ML system is enormous. You need a pipeline that handles data ingestion, feature engineering, training, validation, deployment, and monitoring as a repeatable, automated process. Without this, your "AI product" is a notebook that a data scientist reruns manually every week.
Pattern Overview
AI/ML pipeline architecture separates the ML lifecycle into distinct, automated stages: data ingestion and validation, feature engineering and storage, model training and hyperparameter tuning, model evaluation and validation, model serving and inference, and continuous monitoring. Each stage is versioned, reproducible, and observable. The architecture supports both batch (scheduled retraining) and online (real-time feature computation) workflows. A feature store decouples feature engineering from model training, enabling feature reuse across models and consistent features between training and serving.
Reference Architecture
The pipeline flows from data sources (databases, APIs, event streams) through a feature engineering layer that computes and stores features in a feature store (online for serving, offline for training). A training orchestrator runs experiments, logs parameters and metrics, and produces versioned model artifacts stored in a model registry. A deployment pipeline promotes models through staging to production with automated canary evaluation. Model serving runs behind a load balancer with A/B testing support. A monitoring layer tracks prediction drift, data drift, and business metrics to trigger retraining.
- Feature Store: Dual-mode store with an offline component (Parquet/Delta Lake on S3) for training and an online component (Redis/DynamoDB) for low-latency serving. Features are defined once and computed consistently for both training and inference, eliminating the training-serving skew that causes most production ML bugs
- Training Orchestrator: Manages training runs with experiment tracking (MLflow, W&B), hyperparameter optimization (Optuna, Ray Tune), and distributed training for large models (PyTorch DDP, Horovod). Outputs versioned model artifacts with metadata (training data hash, hyperparameters, metrics)
- Model Registry & Deployment: Central registry (MLflow Model Registry, SageMaker Model Registry) that tracks model versions, approval status, and deployment history. CI/CD pipeline that deploys models as containers (TorchServe, Triton, custom Flask/FastAPI) with canary rollout and automated rollback
- Monitoring & Drift Detection: Tracks input data distribution (data drift), prediction distribution (prediction drift), and business metrics (conversion rate, accuracy on labeled samples). Automated alerts when drift exceeds thresholds, with optional automatic retraining triggers

Design Decisions & Trade-offs
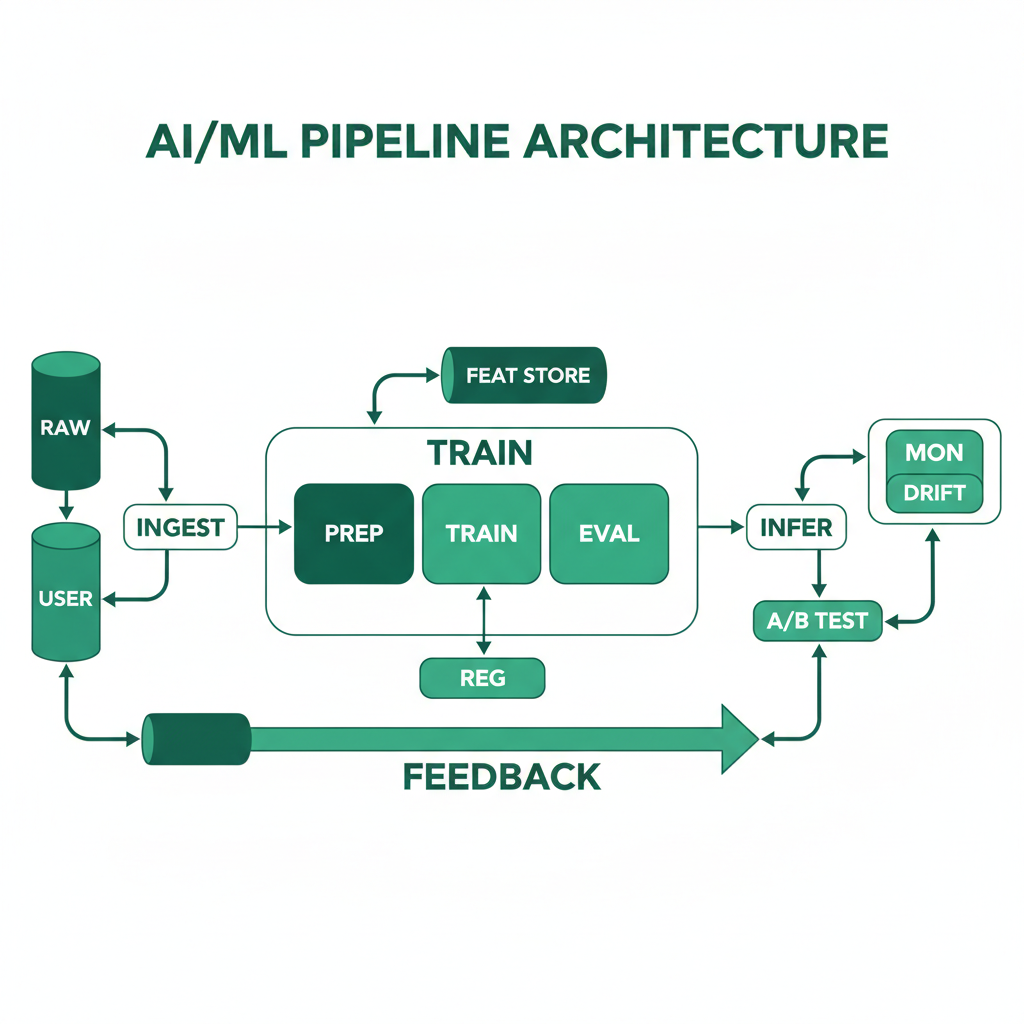
System Architecture Overview
Technology Choices
| Layer | Technologies |
|---|---|
| Training | PyTorch, TensorFlow, scikit-learn, XGBoost, Hugging Face Transformers |
| Orchestration | Kubeflow, SageMaker Pipelines, Airflow, Prefect, Dagster |
| Feature Store | Feast, Tecton, SageMaker Feature Store |
| Model Serving | TorchServe, Triton Inference Server, SageMaker Endpoints, FastAPI |
| Experiment Tracking | MLflow, Weights & Biases, Neptune |
| Monitoring | Evidently AI, WhyLabs, custom Prometheus metrics |
When to Use / When to Avoid
| Use When | Avoid When |
|---|---|
| You have ML models in production that need regular retraining | You're still exploring whether ML solves the problem — start with notebooks |
| Multiple models share features and need consistent feature engineering | You have one model retrained quarterly — a script and cron job may suffice |
| You need reproducible training with versioned data, code, and models | The ML component is a single API call to a hosted LLM (use AI SDK patterns instead) |
| Model performance degradation directly impacts business metrics | The team doesn't have ML engineering skills to operate the pipeline |
Our Approach
MW builds ML pipelines with a "production-first" mindset — we start with the serving and monitoring infrastructure before optimizing the model. A mediocre model in a robust pipeline beats a great model in a notebook. Our pipelines include automated data validation (Great Expectations), training-serving skew tests, shadow mode deployment (new model receives traffic but doesn't serve results), and gradual rollout with automatic rollback on metric regression. We've deployed pipelines handling 50M+ predictions/day across healthcare, fintech, and computer vision domains.

Related Blueprints
- AI Medical Records Assistant — NLP pipeline for medical document understanding
- AI Code Review & QA Agent — ML models for code analysis and defect prediction
- AI Compliance Monitoring Agent — Continuous model inference on regulatory data streams
- Quality Inspection Automation — Computer vision pipeline for manufacturing defect detection
- AI-Powered Medical Imaging Analysis — Medical imaging inference with DICOM integration

Related Case Studies
- AI Surveillance System — Real-time computer vision inference pipeline with model versioning
- Video Analysis — Object tracking and active speaker detection ML pipelines
- Health & Wellness AI — Multi-agent ML system for health coaching recommendations
Related Architecture Patterns
Explore more design patterns and system architectures

Scalable Vector Database Architecture
Embedding search is easy at 10K vectors. At 100M vectors with sub-100ms P99, it's an infrastructure problem — and that's what this pattern solves.

RAG Pipeline Architecture
Give your LLM access to your data without fine-tuning. RAG bridges the gap between general-purpose language models and domain-specific knowledge.

Data-Intensive Platform Architecture
When your competitive advantage is in your data, the platform that collects, transforms, stores, and surfaces that data is the most important thing you'll build.
Need Help Implementing This Architecture?
Our architects can help design and build systems using this pattern for your specific requirements.
Get In Touch