Back to Architecture Patterns
DataEnterprise
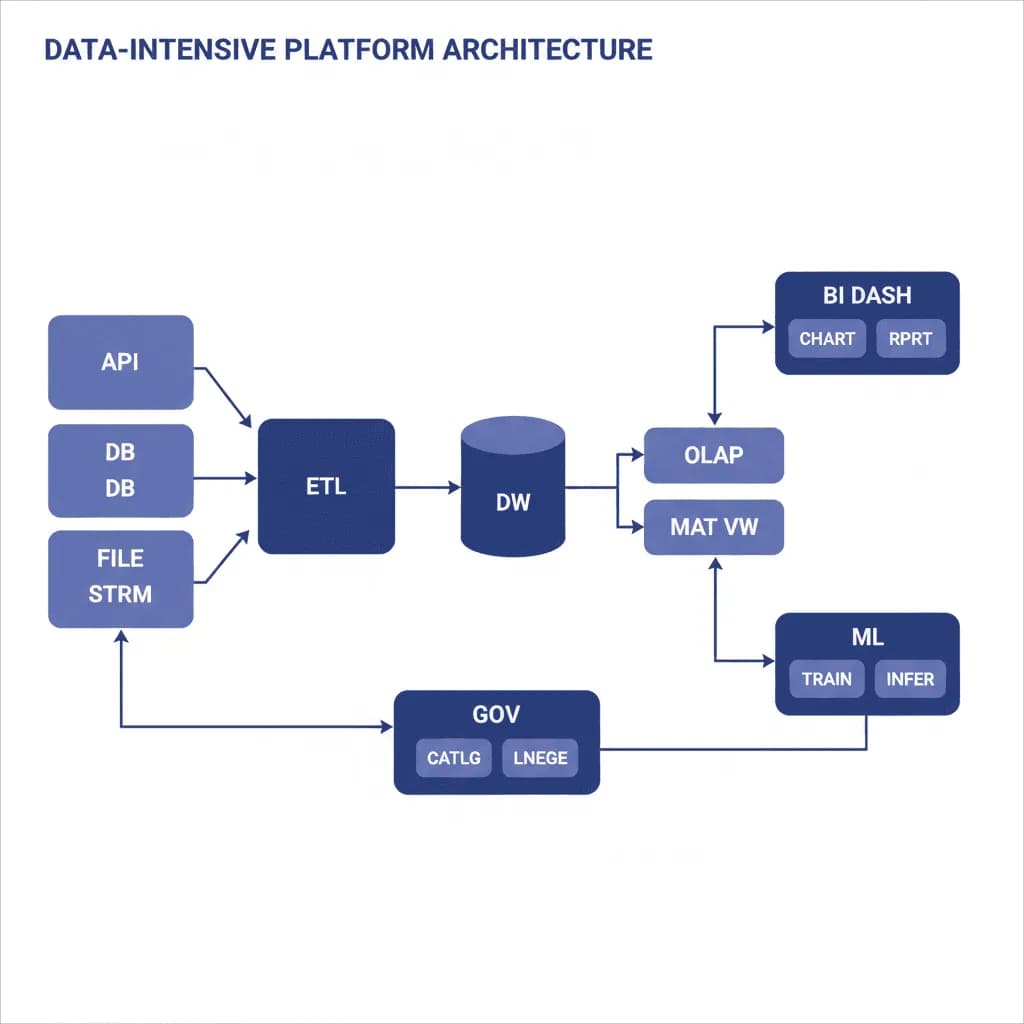
Data-Intensive Platform Architecture
When your competitive advantage is in your data, the platform that collects, transforms, stores, and surfaces that data is the most important thing you'll build.
|
Discuss This Architecture3 topics covered
Data
Category
Enterprise
Complexity
Healthcare, Financial Services
Industries
3+
Technologies

When You Need This
Your organization has data scattered across dozens of systems — CRM, ERP, billing, support tickets, sensor data, third-party APIs — and nobody can answer basic business questions without a week of manual data pulling. Reports are built in spreadsheets, analysts wait days for data engineering to prepare datasets, and the "single source of truth" is whichever database someone queried last. You need a data platform that ingests from all sources, transforms data into analysis-ready models, and serves insights to both dashboards and AI/ML systems. This isn't a data warehouse project — it's a platform that makes data a usable organizational asset.
Related Architecture Patterns
Explore more design patterns and system architectures


Need Help Implementing This Architecture?
Our architects can help design and build systems using this pattern for your specific requirements.
Get In Touch